Ingeniería de Software Agéntica: Guía Completa de ALMAS, OpenCode y Gemini 3
Explora el futuro del desarrollo de software con agentes LLM: framework ALMAS, ecosistema OpenCode y Gemini 3. Análisis de calidad, seguridad y QA autónomo.

Visión General del Framework ALMAS
ALMAS (Autonomous LLM-based Multi-Agent Software Engineering) es un marco de trabajo diseñado para automatizar el ciclo de vida de desarrollo de software (SDLC) mediante el uso de múltiples agentes basados en modelos de lenguaje extenso (LLM). A diferencia de las herramientas aisladas que solo completan código, ALMAS busca integrarse como un ecosistema que cubre desde la gestión de productos hasta la revisión de código. Su objetivo es funcionar dentro de equipos ágiles, permitiendo que los agentes colaboren perfectamente con desarrolladores humanos y herramientas industriales como Jira y Bitbucket.
La Filosofía de las "Tres Ces"
El diseño de ALMAS se fundamenta en tres pilares estratégicos denominados las "tres Ces": Consciente del contexto (Context-aware), Colaborativo y Costo-efectivo. Este enfoque garantiza que los agentes especializados no solo se comuniquen entre sí de manera fluida, sino que también interactúen con sus compañeros humanos de forma que se reduzca la carga cognitiva y se mejore la productividad general. La modularidad del sistema permite que cada agente tenga objetivos específicos, lo que facilita el manejo de tareas complejas.
Alineación de Agentes con Roles Ágiles
Una de las innovaciones más destacadas de ALMAS es la alineación de sus agentes con los roles diversos encontrados en equipos de desarrollo centrados en humanos y metodologías ágiles. El sistema despliega agentes ligeros para tareas rutinarias y de baja complejidad, mientras asigna agentes avanzados para decisiones arquitectónicas y de integración complejas. Esto emula las jerarquías de los equipos reales, desde gerentes de producto y planificadores de sprint hasta desarrolladores y revisores pares.
El Agente de Sprint: Planificación y Estimación
El Sprint Agent actúa como Product Manager y Scrum Master dentro del framework. Su función principal es refinar las tareas del usuario para asegurar claridad y completitud, desglosándolas en sub-tareas con descripciones detalladas, criterios de aceptación y estimaciones de esfuerzo. Los criterios de aceptación son vitales para las pruebas unitarias posteriores, mientras que la estimación de esfuerzo utiliza aprendizaje de pocos disparos (few-shot learning) basado en ejemplos pasados para mejorar la precisión.
El Agente Supervisor: Orquestación y Asignación
El Supervisor Agent es responsable de la orquestación dinámica del sistema, asignando sub-tareas a los LLMs más adecuados según el costo y el rendimiento. Mantiene un grupo diverso de agentes y rastrea sus acciones para asegurar que el flujo de trabajo progrese correctamente. Si la recuperación automatizada de errores falla tras varios intentos, este agente transfiere el control a un desarrollador humano, entregando un historial de acciones resumido para facilitar la intervención.
Agentes de Resumen y Control: Gestión del Contexto
Para superar las limitaciones de la ventana de contexto de los LLMs, ALMAS introduce los agentes de Resumen (Summary Agent) y Control (Control Agent).
- Summary Agent: Genera resúmenes en lenguaje natural para cada unidad de código, creando una representación compacta y agnóstica del lenguaje del repositorio.
- Control Agent: Utiliza estos resúmenes para localizar el código relevante para cada sub-tarea, permitiendo una ejecución más precisa sin saturar la memoria del modelo.
Meta-RAG: Recuperación Avanzada en Grandes Repositorios
ALMAS implementa una estrategia de recuperación novedosa denominada Meta-RAG. Esta técnica combina la Generación Aumentada por Recuperación (RAG) con los resúmenes dinámicos de código para mejorar la localización de errores y el desarrollo de nuevas funciones en bases de código extensas. Al actuar como su propio recuperador para la planificación y ejecución, el sistema mitiga la dilución de la atención que ocurre cuando se utilizan prompts demasiado largos.
Desarrollo Colaborativo: Interacción Humano-IA
El diseño de ALMAS permite que los agentes trabajen junto a desarrolladores humanos de manera modular. Los programadores pueden elegir integrar selectivamente agentes específicos, como el de Sprint o el de Revisión de Pares, en su flujo de trabajo existente. Esta flexibilidad permite reemplazar o combinar diferentes soluciones de generación de código, mejorando la productividad sin forzar una automatización total si el equipo prefiere supervisión manual constante.
Agentes de Revisión y Validación de Código
La calidad del código se asegura a través de dos figuras clave:
- Developer Agent: Verifica el formato y la compilación del código generado.
- Peer Agent: Realiza revisiones exhaustivas evaluando funcionalidad, vulnerabilidades, rendimiento y posibles alucinaciones. Produce un informe detallado para la revisión humana.
Si las pruebas unitarias fallan, el Control Agent se activa automáticamente para localizar y abordar los problemas detectados.
Estrategias de Eficiencia de Costos
ALMAS busca reducir los costos operativos mediante el uso estratégico de recursos. Al condensar la base de código en resúmenes de lenguaje natural, se reduce significativamente el uso de tokens, que es un factor determinante en el costo de los LLMs. Además, el Supervisor Agent optimiza el gasto al enrutar tareas específicas a modelos más pequeños o económicos cuando la complejidad de la tarea no requiere la potencia de un modelo de gama alta.
Análisis de Calidad y Seguridad en la IA de Código
El "Calidad-Gap" en el Código Generado por IA
Un estudio cuantitativo realizado sobre 4,442 tareas de Java revela que, aunque los LLMs pueden generar código funcional, a menudo introducen defectos de software significativos, incluyendo errores, vulnerabilidades de seguridad y "code smells". Este "gap" de calidad indica que el código generado por IA no está listo para producción de manera inmediata y requiere una verificación rigurosa mediante análisis estático y revisión humana para evitar riesgos latentes.
Desmitificación de los Benchmarks de Rendimiento
Una conclusión crítica de las investigaciones es que no existe una correlación directa entre el rendimiento funcional de un modelo (tasa de aprobación de pruebas) y la calidad o seguridad general de su código.
Ejemplo: Claude Sonnet 4 mostró la tasa de éxito más alta en pruebas (77.04%), pero también promedió más problemas de análisis estático por tarea exitosa (2.11) en comparación con modelos más pequeños como OpenCoder-8B (1.45). Esto sugiere que los benchmarks actuales son insuficientes para evaluar la robustez real del software.
Análisis de "Code Smells" y Mantenibilidad
Los "code smells" representan el 90-93% de los problemas detectados en el código generado por IA. Aunque no son errores funcionales directos, afectan negativamente la legibilidad, mantenibilidad y evolución del sistema, contribuyendo a la acumulación de deuda técnica. Los problemas más comunes incluyen:
- Código muerto o redundante.
- Violaciones de mejores prácticas de diseño.
- Visibilidad inadecuada de campos y variables.
Errores Comunes: Lógica y Flujo de Control
Los errores funcionales o "bugs" identificados suelen originarse en fallos de razonamiento profundo. Los errores de flujo de control, como bloques condicionales siempre verdaderos o falsos y lógica de ramificación incorrecta, son especialmente prevalentes en modelos como GPT-4o (48.15% de sus bugs). Estos fallos sugieren que los modelos priorizan la plausibilidad sintáctica sobre la integridad funcional completa en rutas de ejecución complejas.
Vulnerabilidades Críticas de Seguridad
Aunque las vulnerabilidades de seguridad representan solo aproximadamente el 2% de los problemas totales, su impacto es severo. Se han identificado 67 tipos distintos de vulnerabilidades, siendo las más graves:
- Path-Traversal.
- Inyección.
Estas fallas permiten la manipulación no autorizada de archivos y ocurren porque los LLMs a menudo no realizan un análisis de "taint" no local para rastrear cómo los datos del usuario llegan a sumideros sensibles.
El Riesgo Persistente de Credenciales "Hard-coded"
El análisis estático detectó instancias de contraseñas y claves API grabadas directamente en el código (hard-coded) en todos los modelos evaluados. Esta vulnerabilidad es particularmente común en la familia Llama, donde casi el 30% de sus vulnerabilidades eran de este tipo. Los modelos parecen tratar estas cadenas sensibles como literales de texto benignos, replicando patrones inseguros presentes en sus datos de entrenamiento.
Manejo de Errores Deficiente y Deuda Técnica
Modelos como Claude Sonnet 4, GPT-4o y Llama 3.2 90B tienden a usar excepciones genéricas en lugar de tipos de error dedicados. Esta falta de especificidad dificulta el diagnóstico de fallos en producción y es una señal de que los modelos intentan evitar errores de ejecución inmediatos a costa de la claridad arquitectónica. Además, la generación de clases vacías o métodos redundantes contribuye al crecimiento innecesario de la base de código.
Fallos en la Gestión de Recursos
El incumplimiento en el cierre adecuado de recursos, como flujos de datos o conexiones de red, fue identificado como un error de nivel "Blocker" recurrente. SonarQube detectó numerosas violaciones de la regla de uso de try-with-resources. Esto refleja la dificultad de los LLMs para planificar y rastrear ciclos de vida de recursos que se extienden más allá de una vista de contexto local.
Evolución de Modelos: Claude 3.7 vs. Claude 4

La comparación entre generaciones de modelos muestra que el progreso no es uniforme. Aunque Claude Sonnet 4 mejoró su puntuación funcional respecto a Claude 3.7, la proporción de errores críticos (Blocker) casi se duplicó (de 7.1% a 13.71%). Esto indica que a medida que los modelos se vuelven más capaces de generar soluciones sofisticadas, también pueden introducir riesgos de mayor gravedad.
Análisis Estático como Salvaguarda Esencial
Las herramientas como SonarQube proporcionan un mecanismo de protección automatizado y consistente contra los patrones negativos de la IA. Dado que los LLMs son probabilísticos, el carácter determinante y basado en reglas del análisis estático ofrece un contrapeso vital para asegurar que el código cumpla con los estándares profesionales. La integración de estas herramientas en tuberías de CI/CD permite una validación continua.
Calidad de Software y QA Autónomo
QA Autónomo en Aplicaciones Cloud-Native
La integración de agentes de GenAI en las pruebas funcionales representa un cambio de paradigma para las aplicaciones en la nube. Estos agentes abordan los problemas de escalabilidad en arquitecturas de microservicios, donde la complejidad de las pruebas aumenta exponencialmente. Las organizaciones que implementan estos marcos reportan una reducción del tiempo de prueba de hasta un 65%.
Reducción de Carga de Ingeniería en Pruebas
Los agentes de IA pueden automatizar la generación, ejecución y mantenimiento de suites de pruebas en capas de unidad, componente e integración. Esto permite que el QA evoluione de una ejecución táctica a una supervisión estratégica, eliminando los cuellos de botella del esfuerzo manual tradicional.
Capa de Adquisición de Contexto para Testing
El uso de contextos multimodales (código, documentación, especificaciones de API) aumenta la precisión de las pruebas en un 83.7% en comparación con enfoques que solo analizan el código. Además, el uso de RAG mejora la detección de dependencias mediante modelos de relación basados en grafos.
Orquestación Multi-Agente en Calidad de Software
Los sistemas multi-agente orquestados superan a los enfoques monolíticos en un 47.3% en tareas de prueba compuestas. La arquitectura recomendada incluye:
- Agentes de dominio especializados.
- Agentes de coordinación para la gestión de recursos.
- Agentes de evaluación para calificar los resultados de calidad.
Impacto en la Velocidad de Entrega y Detección de Errores
La implementación de testing impulsado por GenAI ha demostrado:
- Detectar un 56% más de casos de borde que los enfoques manuales.
- Reducir el mantenimiento de pruebas en un 43%.
- Mejorar la cobertura en un 51% en microservicios complejos.
- Acelerar el tiempo de comercialización en un 37%.
- Reducir un 29% los incidentes de producción.
Transformación del Rol del Profesional de QA
La adopción de IA reduce los esfuerzos de prueba manual en un 57%. Los ingenieros de QA pasan de escribir scripts a formular estrategias y gobernanza de calidad, dedicando 3.2 veces más tiempo a iniciativas estratégicas. Aunque la demanda de habilidades manuales disminuye, la necesidad de expertos en ingeniería de prompts y arquitectura de calidad aumenta drásticamente (183%).
Implicaciones Económicas de la Calidad Autónoma
El uso de agentes de GenAI para pruebas unitarias genera un ROI promedio del 32.8% en el primer año. Las organizaciones reportan la recuperación de miles de horas de ingeniería, equivalentes a millones de dólares redirigidos hacia la innovación.
El Ecosistema de Google: Gemini 3 y Antigravity
Introducción a Gemini 3 y sus Capacidades Agénticas
Google ha lanzado Gemini 3 Pro, optimizado específicamente para flujos de trabajo agénticos y tareas de programación. Este modelo supera a versiones anteriores en benchmarks de codificación y razonamiento visual. Una de sus funciones destacadas es el "vibe coding", que permite crear aplicaciones interactivas completas a partir de prompts en lenguaje natural.
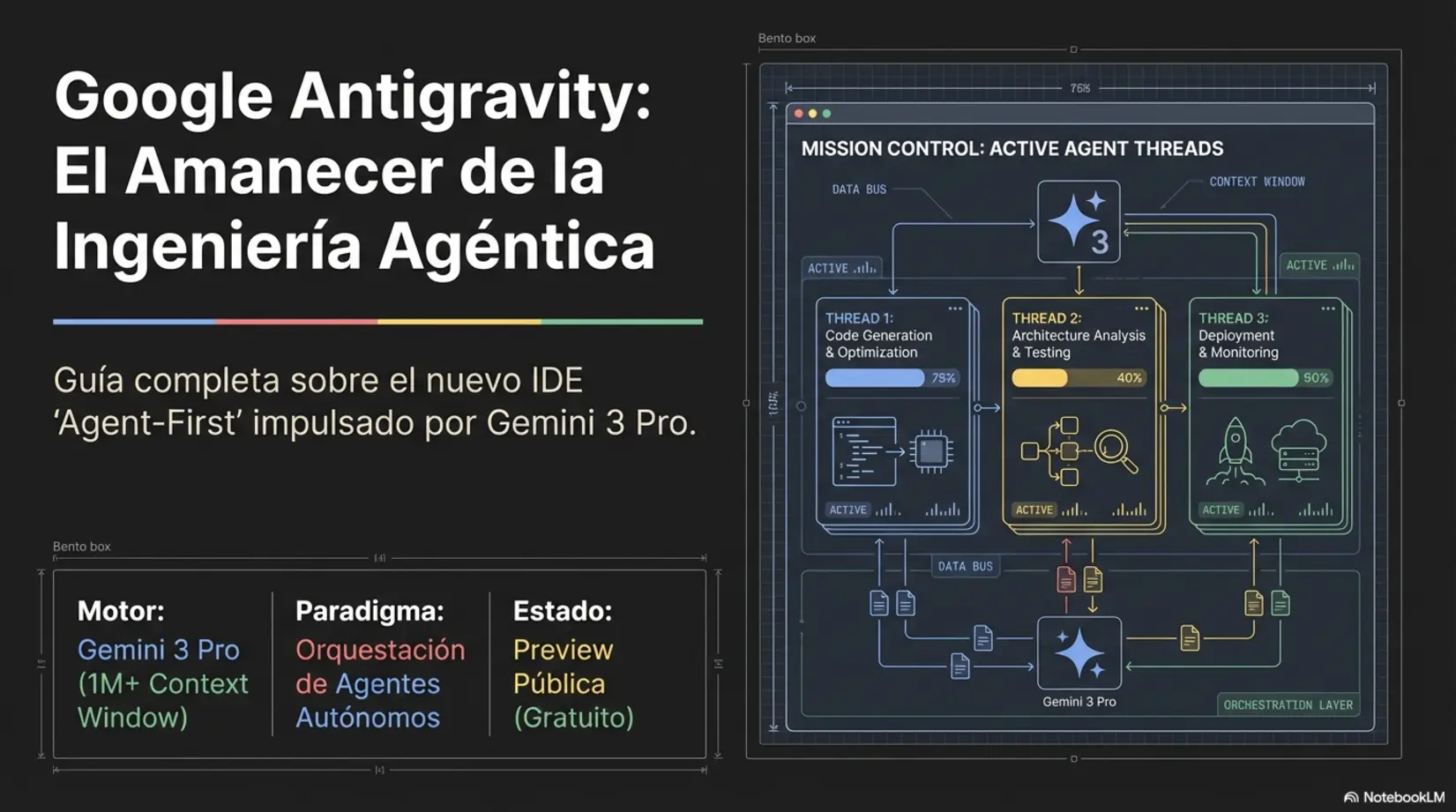
Google Antigravity: El IDE "Agent-First"
Google Antigravity es una plataforma de desarrollo agéntica diseñada para operar a un nivel orientado a tareas. Es una bifurcación (fork) de Visual Studio Code que prioriza la gestión de agentes sobre la edición de texto tradicional. Permite que el desarrollador actúe como arquitecto, colaborando con agentes que operan de forma autónoma en el editor, la terminal y el navegador.
Vista del Manager vs. Vista del Editor en Antigravity
La interfaz se divide en dos ventanas principales:
- Agent Manager: Centro de control de misión para definir objetivos de alto nivel (refactorizar, generar pruebas) y supervisar agentes asíncronos.
- Editor: Mantiene la familiaridad de VS Code para ajustes manuales y sugerencias intercaladas.
Artefactos: Solucionando la "Brecha de Confianza"
Para generar confianza, Antigravity produce "Artefactos": entregables verificables como planes de implementación, listas de tareas, capturas de pantalla y grabaciones de video. Estos permiten verificar el cumplimiento de requisitos funcionales sin leer cada línea de código de inmediato.
Integración con Navegador y Terminal
Antigravity incluye un subagente de navegador especializado para validar aplicaciones en tiempo real interactuando con el DOM. Además, cuenta con herramientas de bash que permiten al modelo proponer y ejecutar comandos de shell bajo políticas de seguridad configurables.
Vibe Coding: El Lenguaje Natural como Sintaxis
El "vibe coding" con Gemini 3 Pro implica que el lenguaje natural es la única sintaxis necesaria. El modelo maneja la planificación de múltiples pasos y los detalles técnicos, permitiendo a los creadores centrarse en la visión creativa. Lidera actualmente el ranking de WebDev Arena.
Razonamiento Multimodal y Espacial en Gemini 3
Gemini 3 destaca en el razonamiento complejo de imágenes y video, con una ventana de contexto de 1 millón de tokens. Su comprensión espacial permite aplicaciones en robótica y realidad extendida (XR), además de ofrecer "comprensión inteligente de pantalla" para identificar intenciones basadas en movimientos del mouse.
Workflow Dual: Gemini 3 Pro + Claude Opus 4.5
Se sugiere un flujo híbrido:
- Gemini 3 Pro: Para generación rápida de front-end y UI.
- Claude Opus 4.5: Para planificación arquitectónica profunda y razonamiento de back-end.
Políticas de Seguridad y Permisos en Antigravity
Antigravity permite configurar:
- Modo Seguro: Restringe acceso a recursos externos.
- Políticas de Terminal: Opciones de "Solicitar revisión" o "Turbo" (ejecución automática).
- Listas blancas: Para dominios permitidos en el navegador.
Personalización: Reglas vs. Flujos de Trabajo
- Reglas: Instrucciones constantes del sistema (ej. estilo PEP 8).
- Flujos de Trabajo: Instrucciones guardadas activadas con
/(ej./generate-unit-tests).
Comparativa en el Mundo Real
| Modelo | Perfil de Rendimiento |
|---|---|
| Claude 4.5 | Arquitecturas detalladas, pero puede fallar en casos de borde. |
| GPT-5.1 Codex | El más estable y fiable para integración directa. |
| Gemini 3 Pro | El más rápido, código limpio, requiere revisión de casos límite. |
Analogía de la Manufactura: Mejorar el Sistema, no el Código
El papel del desarrollador muta hacia la configuración de sistemas agénticos. Como en la manufactura moderna: si una pieza es defectuosa, se ajusta la máquina, no solo la pieza. El desarrollador se convierte en auditor y arquitecto de la IA.
El Futuro: De Programadores a Arquitectos de IA
El éxito se medirá por métricas como el porcentaje de código escrito por agentes y la cantidad mínima de prompts necesarios antes de un merge request (apuntando a menos de 5). La habilidad principal será validar y aprobar salidas de calidad.
Análisis Específico de OpenCode
El Ecosistema de OpenCode
OpenCode es un agente de codificación de IA de código abierto disponible mediante terminal (TUI), escritorio o extensión de IDE. Su arquitectura permite realizar tareas complejas en lugar de simples completados.
Flexibilidad de Proveedores y Modelos
Permite configurar cualquier proveedor de LLM. Ofrece OpenCode Zen, una lista de modelos verificados por el equipo para garantizar eficacia en programación.
El Modelo OpenCoder-8B como Motor
Basado en Llama-3.1-8B, este modelo es un "libro de cocina abierto". En pruebas, generó el código más conciso (120,288 líneas para 4,442 tareas).
Inicialización y Análisis de Proyecto: AGENTS.md
El comando /init genera un archivo AGENTS.md que ayuda al agente a comprender la arquitectura y los patrones de codificación del repositorio. Se recomienda incluirlo en Git.
Flujos de Trabajo y Operación en OpenCode
Dualidad de Modos: Plan vs. Build
- Plan Mode: Analiza y sugiere la estrategia sin realizar cambios directos.
- Build Mode: Realiza las modificaciones reales una vez aceptado el plan.
Interacción Multimodal y Contexto Visual
Permite arrastrar y soltar imágenes en la terminal para implementar interfaces basadas en bocetos o diseños previos.
Comandos de Control y Gestión de Errores
- /undo: Revierte cambios.
- /redo: Vuelve a aplicar cambios revertidos.
- /share: Enlace a la conversación (privado por defecto).
Localización y Búsqueda Contextual
Usa la tecla @ para activar una búsqueda difusa (fuzzy search) de archivos, permitiendo preguntas específicas sobre la lógica existente.
Calidad y Seguridad del Código en OpenCode
Desempeño Funcional de los Modelos Abiertos
OpenCoder-8B registró un Pass@1 del 60.43%. Aunque es conciso y tiene baja densidad de problemas generales (1.45 por tarea), presenta riesgos específicos.
Riesgos de Seguridad Inherentes
OpenCoder-8B presenta una alta densidad de vulnerabilidades críticas (Blocker), alcanzando el 64.18% de sus fallos. Incluye credenciales hard-coded e inyecciones.
Gestión de Deuda Técnica y Code Smells
El 42.74% de los problemas en OpenCoder-8B son código muerto o redundante, debido a la falta de visión global del proyecto en ciertas ejecuciones.
Personalización y Extensibilidad
OpenCode permite configurar temas, keybinds y comandos. Es compatible con MCP (Model Context Protocol) y soporte para ACP para ampliar habilidades del agente.
Métodos de Instalación Versátiles
Disponible vía npm, Bun, pnpm, Yarn, Homebrew, Chocolatey, Scoop y Docker.
El Futuro del Desarrollo Agéntico con OpenCode
La filosofía de OpenCode busca que el desarrollador pase menos tiempo escribiendo sintaxis y más tiempo refinando planes y validando calidad, asegurando una transición transparente y adaptable para los equipos de ingeniería.
¿Listo para despegar?
Si buscas una web rápida, segura y diseñada para convertir, solicita tu presupuesto sin compromiso.
Solicitar PresupuestoArtículos Relacionados
Guía Definitiva de Google Antigravity : El IDE Agent-First que Revoluciona el Desarrollo
Aprende todo sobre Google Antigravity, Gemini 3 Pro y cómo crear aplicaciones con agentes de IA autónomos. Guía complet...